![[Previous]](arrow1.gif)
![[Up]](arrow2.gif)
![[Next]](arrow3.gif)
A Tour of NTL: Summary of Changes
2025.11.07: Changes between NTL 11.5.1 and 11.6.0
-
Improved performance on Aarch64 (including Apple Silicon):
-
Introduced code using a few Neon intrinsic that boosts the performance
of GF2X (using Neon's intrinsic for carry-less multiplication)
and Mat<zz_p> (using Neon's intrinsics for basic SIMD
floating point).
The improvements to Mat<zz_p> also improve
Mat<ZZ_p>.
-
Speedups on Apple M1 Max:
-
7x for degree 10,000 poly mul over GF(2)
-
5x for 1000x1000 matrix mul mod 20-bit prime
-
2x for 1000x1000 matrix mul mod 1000-bit prime
-
I initially tried using
SIMDE,
but ran into some limitations that made it unworkable for this
application — it didn't give me CLMUL or FMA.
Moreover, I really only needed
about 100 lines of intrinsics code to do what I needed,
which was not that hard to put together from scratch.
-
Updated the strategy for getting the compiler to fully exploit
the native instruction set.
-
The configuration script will now create
a makefile that compiles with -mcpu=native rather than
-march=native when it detects an Arm machine.
-
It turns out that for historical reasons, while -march=native
is the appropriate option for x86, -mcpu=native
is the appropriate option for Arm.
-
Other updates to the configuration script
(see tour-unix.html
and config.txt for more details):
-
added configure options
ENABLE_LIBTOOL, PREFER_PIC, ENABLE_RPATH,
SYS_PREFIX
-
added some -Wl,-rpath
incantations to make sure we link to the right shared libs
(not needed on macOS, but needed on Linux)
-
a pkg-config file ntl.pc is generated and installed
in $(PREFIX)/lib/pkgconfig
-
an example user makefile USER_MAKEFILE.txt
(tailored to the current build of NTL and the user's OS, and including
helpful comments) is generated and installed in
$(PREFIX)/include/NTL
-
This will hopefully simplify the life if users who want to easily use
NTL after it is installed
-
the configuration log file ConfigLog.h is now called
CONFIG_LOG.txt
(also installed in $(PREFIX)/include/NTL)
-
modified the makefile so that $(DSTDIR)$ is used in
"make uninstall"
-
Updated and simplified documentation regarding
building NTL (see tour-unix.html,
tour-gmp.html,
tour-gf2x.html,
config.txt for more details)
-
Added a "quick start guide" in the README file
2021.06.23: Changes between NTL 11.5.0 and 11.5.1
-
Fixed bug that prevented compilation on IBM Z.
2021.06.20: Changes between NTL 11.4.4 and 11.5.0
-
Added a new configuration option NTL_RANDOM_AES256CTR.
The default is off.
Configure with NTL_RANDOM_AES256CTR=on
to replace the default ChaCha20 Pseudo-Random Number Generator (PRNG)
with 256-bit AES counter mode.
On certain plaforms (modern x86 and IBM System/390x),
special instructions are exploited to improve performance.
Using AES in place of ChaCha may break inter-operability of
applications that depend on the behavior of the PRNG.
Using AES in place of ChaCha may affect the performance positively
or negatively.
On IBM System/390x, there is a marked performance improvement.
On x86 there may be a moderate performance improvement
or degredation.
On any other platforms, where there is no hardware support
for AES (or none that is exploited by NTL), there will likely be a marked performance
degredation.
Thanks to Patrick Steuer for contributing this code.
2021.03.05: Changes between NTL 11.4.3 and 11.4.4
-
Improved Karatsuba code for ZZX and GF2EX
(as well as the non-GMP implementation of ZZ).
(Thanks to Marco Bodrato)
2020.01.04: Changes between NTL 11.4.2 and 11.4.3
-
Fixed bug in build logic that prevented compilation
when not using the GF2X library.
2019.12.31: Changes between NTL 11.4.1 and 11.4.2
-
Fixed GF2X library usage so that it now works with GF2X-v1.3.
-
Fixed a bug in FFT.cpp that could be triggered
when compiling in some legacy modes.
-
Added KarMul and KarSqr for ZZ_pX
(declared in ZZX.h and implemented
in ZZX.cpp).
These are not a part of the documented interface.
-
A few other minor internal modifications.
2019.10.08: Changes between NTL 11.4.0 and 11.4.1
-
Fixed bug in new NTL_EXEC_DIVIDE that
could manifest itself when NTL_THREAD_BOOST=off.
Existing code that does not explicitly use this feature
should not be affected by this bug.
-
Fixed some namespace visibility issues in the TLS hack macros.
2019.09.24: Changes between NTL 11.3.4 and 11.4.0
2019.09.07: Changes between NTL 11.3.3 and 11.3.4
-
Changed NTL's build system so that if NTL_THREADS=on
(which is the default) and SHARED=on
(which is not the default), NTL's makefile will now pass
-lpthread to libtool when it builds the library.
On most platforms, this should allow users to forgo passing
the -pthread option to their compiler when linking.
-
Made the build system's check of correct multithreading behavior
a bit more robust.
2019.09.02: Changes between NTL 11.3.2 and 11.3.3
-
Changed "TLS hack" implementation to use fewer pthread keys
(I did not realize these were a "scarce resource").
-
Implemented xdouble to double conversion to be more
efficient for exponents of large magnitude.
-
Changed some internal interfaces (for FFTRoundUp) to
be simpler and (in rare circumstances) to yield somewhat
more efficient code.
2018.11.15: Changes between NTL 11.3.1 and 11.3.2
-
Fixed a somewhat embarrassing performance issue
in the PowerMod function for the ZZ class
(which also impacts the prime testing and generation functions).
When using GMP, NTL will now call GMP's mpz_powm
function.
Although GMP does have an mpn_pown function,
it is not documented, and so cannot be used by NTL.
This means that NTL is now using some mpz-level
functionality, in addition to mpn-level functionality.
-
This leads to a significant speedup (sometimes 2-3x),
especially for numbers
with a small number of limbs.
-
Thanks to Niek Bouman for helping to sort this out.
2018.10.20: Changes between NTL 11.3.0 and 11.3.1
-
Fixed a bug that effected image, kernel,
and gauss routines for Mat<zz_p>.
These routines did not behave correctly when the
input matrix was zero.
Also improved the mat_lzz_pTest program.
2018.08.17: Changes between NTL 11.2.1 and 11.3.0
-
Implemented an AVX-based small-prime FFT (which works with
both AVX2 and AVX512)
-
Implemented AVX512 instruction sequences
-
This affects Mat<zz_p> arithmetic and the small-prime FFT.
-
Becuause AVX512 instructions can in certain situations
lead to slower computations (because of CPU "throttling"),
this feature can be disabled by configuring with
NTL_AVOID_AVX512=on.
-
Performance tuned GF2EX arithmetic
-
Tuned crossovers for various algorithms.
-
Implemented asymptotocially fast GCD and XGCD for
GF2EX, zz_pEX, and ZZ_pEX
-
Some work may still need to be done to fine tune
the crossovers, but they should be pretty good as is.
-
Many thanks to
Luis Felipe Tabera Alonso for porting the code,
as well as testing and tuning it.
-
Other small changes
-
Restructured quad_float implemenation to isolate better
the parts that are dependent on correct FP rounding.
-
Standardized vector growth rate to 1.5 via the function _ntl_vec_grow.
-
Got rid of most uses of __restrict in mat_lzz_p.cpp,
some of which were technically UB.
-
Got rid of some uses of #warning, which are not portable.
2018.07.15: Changes between NTL 11.2.0 and 11.2.1
-
Fixed an embarrassing bug, introduced in NTL 11.2.0,
in which add(ZZ,ZZ,long)
and sub(ZZ,ZZ,long) would give incorrect result
if third argument was zero.
-
Fixed incorrect libtool version number in NTL 11.2.0.
2018.07.07: Changes between NTL 11.1.0 and 11.2.0
-
Complete re-write of the
Schoenhage-Strassen FFT for ZZX arithmetic.
-
Implementation of "truncated" FFT
-
Implementaion of "sqrt 2" trick
-
More efficient implementation of low-level butterfly operations
-
Here is some timing data comparing ZZX multiplication times
of NTL 11.0 and 11.2.
The entries are the ratio of the 11.0-time over the 11.2-time (so
the bigger the number, the bigger the improvement).
The rows are labeled by the bit-length k of the coefficient,
the column by the degree bound n.
Unlabeled columns represent degree bounds half-way between the labeled
ones.
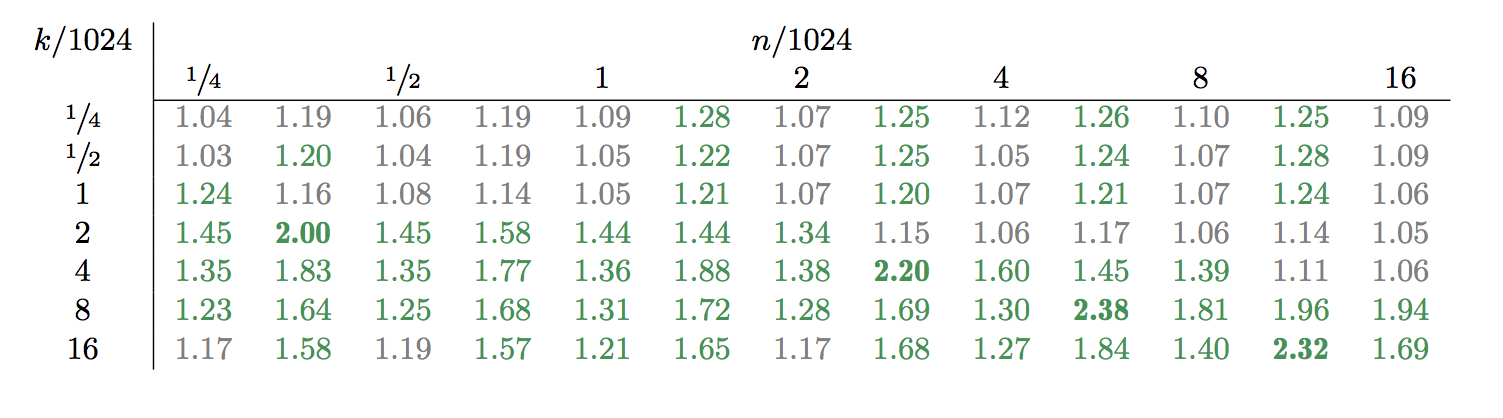
-
For multiplication in ZZX, NTL and
FLINT
now have comparable performance across a wide range
of parameter sizes, with NTL being 2x faster for some parameters,
and FLITNt being 1.5x faster in others.
Here is a chart showing the ratio of FLINT time
over NTL time (so the bigger the number, the faster NTL is relative to FLINT)
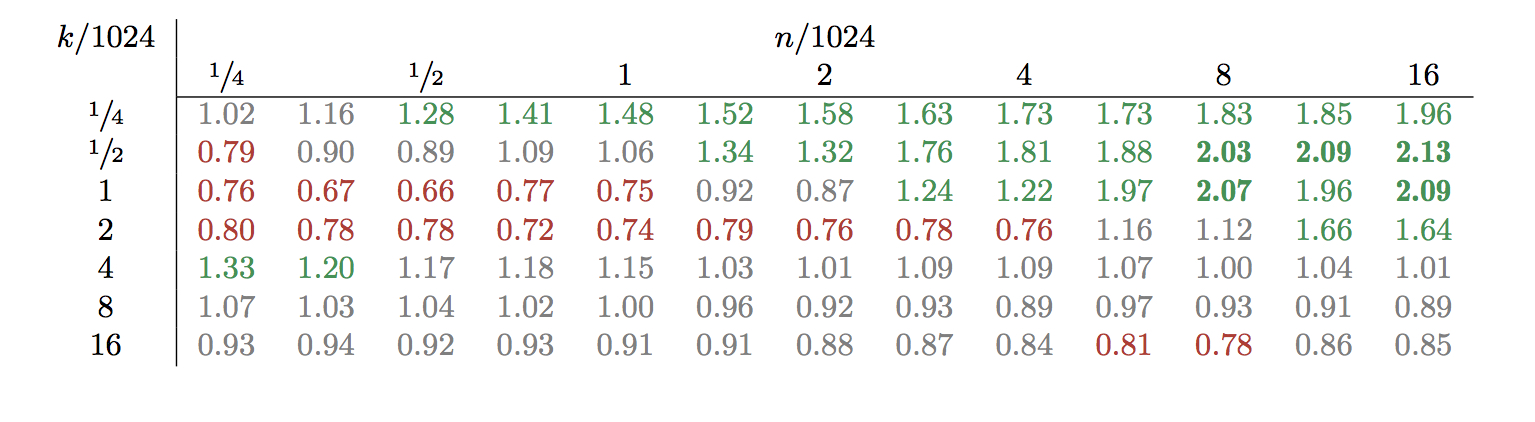
-
See also this report on
NTL vs FLINT
for detailed benchmarks that compare the performance NTL and FLINT
on a number of operations and parameter settings.
-
Future plans for NTL's Schoenhage-Strassen code:
-
Implement something like Bailey's 4-step variant
(which should yield better cache behavior)
-
Thread boosting (built on top of the 4-step variant)
-
Some fine tuning of the new small-prime
truncated-FFT implementation introduced in version 11.0.
-
Fixed obscure bug in new small-prime FFT code: this only affects
users who call low-level, undocumented FFT routines
on transforms of size 2, so it is unlikely to have affected
any real code.
-
Performance improvements to ZZ+long and ZZ-long
routines (and by extension ZZ+=long, ZZ-=long,
ZZ++, and ZZ--)
2018.06.07: Changes between NTL 11.0.0 and 11.1.0
-
Complete re-write of the low-level "small-prime" FFT (a.k.a., NTT).
- This implements a "truncated" FFT, which can speed up
polynomial multiplication by a factor of two, and which
mainly eliminates "jumps" in the running time at powers of two.
The new FFT routines are in fact a bit faster even at powers of two.
- Some low-level interfaces have changed, but these are
all undocumented, so should not cause
any problems for clients that don't inappropriately
use such interfaces.
-
Here is some timing data comparing the new (truncated) FFT to
the old (plain) FFT. x-axis is degree bound,
y-axis is time (in seconds), shown on a log/log scale.
This is the time to multiply two polynomials modulo
a single-precision "FFT" prime (60 bits).
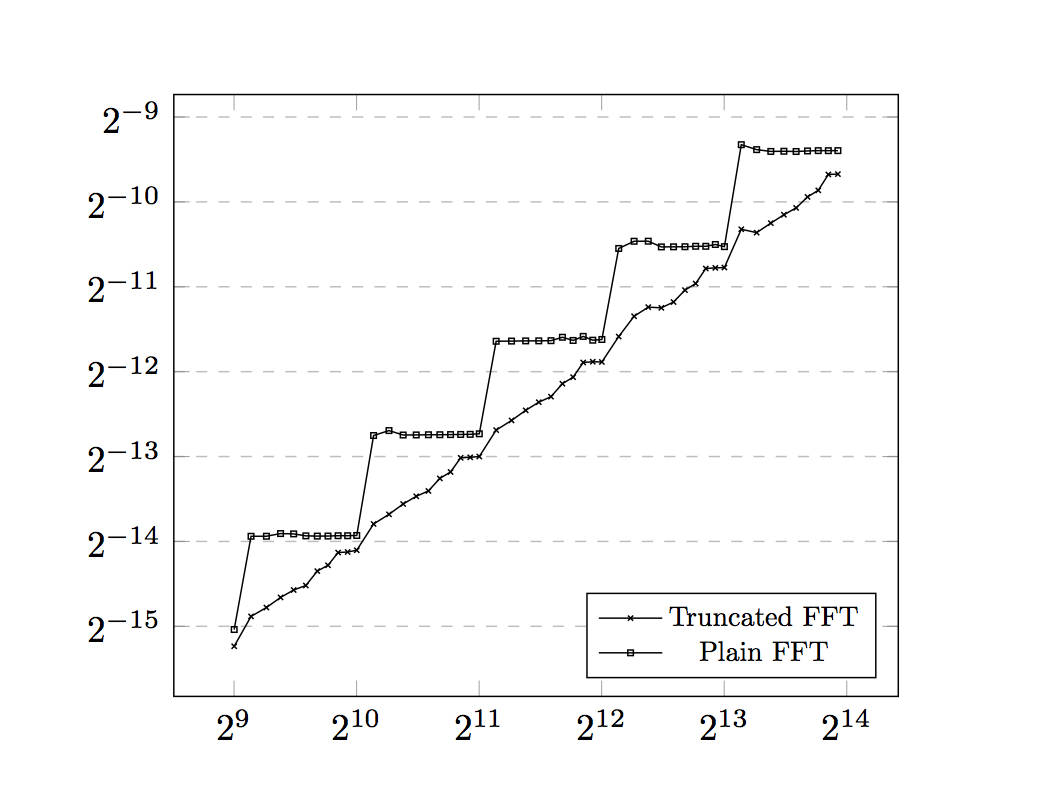
-
Improved performance of ZZ mul and sqr on small inputs
- mul speedup: 1 limb: 2.5x; 2 limbs: 1.4x; 3 limbs: 1.3x.
- NTL now makes explicit calls to mpn_sqr and
requires GMP version 5.0 or later.
-
Other changes:
-
Changed header files to make Windows installation more reliable,
especially for IDE's like Code Blocks
-
Added documentation for the GCD routine in the ZZ module
-
Fixed a bit of UB in the lip.h interface (_ntl_gbigint_body)
2018.04.07: Changes between NTL 10.5.0 and 11.0.0
-
Updated the configuration script:
-
It does some basic auto-detection of the compiler, default language
standard, and hardware platform.
-
Using compiler information, it sets compiler flags
affecting floating point more intelligently.
Note also that the configuration and build scripts ensure
that floating point closely adheres to the IEEE standard,
and that the compiler does not perform any re-association.
-
Using the default language standard information, it sets
the flags affecting language standards more intelligently.
-
Using the hardware platform information,
it sets the TUNE flag more intelligently
(in particular, on x86 platforms, the defaults should work just fine).
-
One now has to run ./configure to generate
a make file,
as the distribution no longer includes a default make file.
-
Running make clobber is no longer of much use,
as the make file will call it automatically if you re-configure.
-
There is now a flag NTL_TLS_HACK that is automatically set
by the configuration script.
This flag controls how TLS (thread local storage) is implemented:
either using pthread routines with __thread
or using only thread_local.
This flag replaces the NTL_DISABLE_TLS_HACK
and NTL_ENABLE_TLS_HACK flags, which had to be set manually.
-
Added a flag NTL_DISABLE_MOVE_ASSIGN,
which is on by default,
and which prevents move assignment operators for
Vec<T> and
Mat<T>.
This disables move assignment
for many other classes, including all of the polynomial classes.
Move assignment can break backward compatibility, as it may
invalidate pointers into the destination vector.
Move constructors are not affected.
-
Added a flag NTL_DISABLE_MOVE, which is off by default.
This disables all move constructors and assignment operators.
It is doubtful that this will ever be needed,
except for really weird client code.
-
Added a check in the the build script to ensure that a thread-safe version of
the GF2X library is used (if necessary).
-
Updated some default configuration values:
-
Made NTL_STD_CXX11=on the default.
-
Made NTL_THREADS=on and NTL_THREAD_BOOST=on
the default.
So now, by default, NTL is thread safe and exploits
multiple cores to speed up many operations,
when possible.
To get these speedups, you just have to call SetNumThreads.
See BasicThreadPool.txt
for more details on thread boosting.
-
Made NTL_SAFE_VECTORS=on the default.
This makes the use of NTL's vectors much safer,
since they do not (by default) rely on
the "relocatability" of the component type.
This mode of operation has also been modified from
previous versions so that it is more backward
compatible (in particular, if the component
type does not have a usable copy or move constructor,
it can still work without compile-time errors).
See vector.txt
for more details.
-
Made NTL_CLEAN_PTR=on the default.
This has no significant impact on performance,
and avoids undefined behavior.
-
Made NTL_NO_INIT_TRANS=on the default.
This means that functions returning class objects
now rely exclusively on the "named return value optimization".
Many years ago, one could not rely on this optimization,
but nowadays, this optimization is essentially universal.
-
Performance improvements:
-
Thread boosted all cubic-time operations in
mat_ZZ_pE,
mat_lzz_pE,
and
mat_GF2E.
This includes:
matrix multiplication, inversion, determinant,
kernel, image, and solving linear systems.
-
Thread boosted RandomPrime, GenPrime,
and GenGermainPrime.
Care has been taken so that
on a given platform,
you will always get the same prime if you run the algorithm
with the same RandomStream. In particular, even though
these routines are thread boosted, their behavior is independent
of the number of available threads and any indeterminacy
arising from concurrent computation.
Also, care has been taken to ensure that the new algorithms
are no slower than the old ones in a single-threaded environment.
-
New functionality:
-
Added a new function GetWallTime.
See tools.txt for details.
-
Added a new function VectorRandomWord.
See ZZ.txt for details.
-
Added support for true variadic templates in various smart pointer
routines.
See SmartPtr.txt for details.
-
Fixes and improvements to the Windows distribution:
-
The Windows distribution has the new default settings as described above.
In particular, the new distribution is thread safe
and thread boosted by default.
-
The distribution has been fixed so that certain linker errors
no longer arise.
-
If the compiler is MSVC++, use of a long long type is
enabled in certain settings for better performance.
-
Some basic testing was done using MSVC++ 2017 to ensure
that the library works with the new default settings.
2017.07.07: Changes between NTL 10.4.0 and 10.5.0
-
Added uniform conversions from char* and const char*,
which use whatever stream input operator >> applies.
-
For example, you can write conv(x, "...")
or x = conv<T>("...")
for x of any type T.
-
The code is written using templates in such a way
that a second argument of 0 or nullptr
will not match.
-
See conversions.txt for details.
-
Changed behavior of matrix input: non rectctanglar matrices
set the fail bit on the stream, rather than raising an error
-
Fixed a benign error on make check.
2017.06.19: Changes between NTL 10.3.0 and 10.4.0
2016.11.18: Changes between NTL 10.2.0 and 10.3.0
-
Implementation of a multi-modular strategy for
matrix multiplication over ZZ_p.
Here are some benchmarks that compare the new strategy
to the old (naive) one.
Here, we consider n-by-n matrices
modulo an n-bit prime.
-
n=128, speedup=6.8x
-
n=256, speedup=8.6x
-
n=512, speedup=9.3x
-
n=1024, speedup=18x
-
n=2048, speedup=37x
I also compared NTL's new mat_ZZ_p multiplication
to FLINT's fmpz_mat
multiplication.
The latter also uses a multi-modular strategy.
For n=128,256,512,1024 as above, NTL's code is between
2.7 and 3.1 times faster than FLINT's
(and we did not count the time it would take to reduce
the entries mod p for the FLINT code).
Part of this may be due to the AVX-enhanced small-prime matrix
multiplication code used by NTL,
and part may be due to better CRT code.
-
I also instrumented both the plain and multi-modular
matrix multiplication for ZZ_p so that they are both "thread boosted"
(i.e., will automatcally exploit multiple cores when possible).
-
As an initial application of this faster matrix multiplication,
I implemented a new version of Brent/Kung modular composition for ZZ_pX,
which is now between 2 and 5 times faster than the old one
(depending on parameters).
This is done with a new class called ZZ_pXNewArgument,
which supersedes ZZ_pXArgument (retained for compatibility).
This also makes the CanZass factoring algorithm
for ZZ_pX faster (sometimes by a factor of almost 2, depending
on parameters).
It also makes CanZass more memory intensive
(but while the overall memory usage increases,
the memory access pattern is fairly cache friendly).
-
I would like to see if this faster matrix multiplication
can be used to get faster linear algebra (determinants, inverses,
more general Gaussian elimination) via reduction to matrix multiplication.
If anyone wants to volunteer to work on this, please let me know.
Presumably, the FLINT nmod_mat code could be repurposed
for this.
I won't have time to work on this for a few months, but would be
glad to discuss ideas with anyone who wanted to do the work.
Note that the "plain" versions of these routines also need
some work.
-
I also added move methods to the Vec and Mat
classes, and made a slight tweak to the Lazy class.
2016.11.10: Changes between NTL 10.1.0 and 10.2.0
-
Added "thread boosting" to the ZZX
multiplication routine.
This can significantly increase performance on
multicore machines (you must configure with NTL_THREAD_BOOST=on
and call SetNumThreads).
-
Marginally improved performance and crossovers for
mat_zz_p multipliplication.
-
Marginally improved performance for
mat_ZZ_p multipliplication (but much bigger
improvements hopefully coming soon).
-
Retired the zz_pXAltArgument class,
which was used for modular composition in zz_pX.
While this has been in in the documented interface
for a few months,
it was flagged as being provisional and subject to
change.
Well, it is being changed: it is being eliminated.
-
In place of zz_pXAltArgument,
I've added a class zz_pXNewArgument.
For the time being, this will also be provisional and
subject to change.
With this class, all the code complexity for improved
performance of modular composition is relegated to
mat_zz_p multiplication.
Also, all modular composition in zz_pX in NTL
goes through this new class.
The old zz_pXArgument remains just for backward compatibility.
2016.10.14: Changes between NTL 10.0.0 and 10.1.0
- Better building
- Vec tweaks
2016.10.08: Changes between NTL 9.11.0 and 10.0.0
- New License: LGPLv2.1+
-
With the permission of all relevant contributors,
NTL is now licensed under
LGPLv2.1+ (the Lesser GNU Public License version 2.1 or later).
-
Previously, NTL was licensed under the GPL.
This new, less restrictive licensing should hopefully increase the
impact of NTL.
- Long integer package restructing
-
I've restructured the long integer package so that the
GMP and "classical LIP" modules share much of the same
code base.
-
This greatly reduces the amount of redundant code,
which will make maintenance easier moving forward.
-
As a bonus, the classical LIP module is simpler,
faster, and (finally) thread safe.
-
As another bonus, the GMP module now is much closer to
being compatible with "non-empty nails".
Although it has not been tested in that mode as of yet,
it may eventually be helpful in the future if I want to replace some
GMP code with code that exploits AVX-512 IFMA instructions.
-
As a part of this transition, "make check" now includes
much more extensive "unit testing" of the long integer package.
-
Despite the drastic changes "under the hood",
this restructuring should not affect at all any
NTL client code that relies only on the documented interface,
including even the ancient legacy interfaces pre-dating NTLv5a
from 2000.
- File name restructuring
-
I've renamed all the ".c" files to ".cpp" files in the Unix distribution.
This seems to be more in line with common practice,
and should make it easier to work with
compilers and other software development tools.
2016.08.22: Changes between NTL 9.10.0 and 9.11.0
-
Improved the effectiveness of the new, faster
ZZ to zz_p conversion
-
Added new routines VectorConv
for faster bulk conversion from ZZ and long
to zz_p
(see lzz_p.txt)
-
There are some hidden interfaces which could be more generally useful,
and I may add these to the documented interface at some point.
-
Added new routines VectorRandomBnd
(see ZZ.txt)
and VectorRandom
(see lzz_p.txt)
for faster bulk random number generation
-
Again, there are some hidden interfaces which could be more generally useful,
and I may add these to the documented interface at some point.
2016.06.21: Changes between NTL 9.9.1 and 9.10.0
-
Fixed a problem in the aligned array logic
that prevented compilation on MinGW on Windows.
-
Conversions from ZZ to zz_p
are now faster, thanks to preconditioning.
Among other things,
the CRT-based ZZX multiplication code is also
a bit faster as a result.
-
The BasicThreadPool class
now guarantees that
exec_range assigns the current thread
first=0, and exec_index assigns
the current thread index=0.
This makes it easy for a thread to tell whether of not
it is the current thread, which can be convienient for
some applications.
-
Fine tuned the interface for SmartPtr
and UniquePtr a bit, including the ability
to attach an explicit deleter policy, which
(among other things) makes it easier to implement the
PIMPL pattern using these classes.
Unfortunately, some of these changes introduced some
minor backward incompatibilities (but I doubt anyone
will even notice).
-
Introduced a new class CopiedPtr,
which has a similar interface to UniquePtr,
but which allows copy and assignment.
This class is meant to replace the OptionalVal
class, whose use is now discouraged.
2016.06.02: Changes between NTL 9.9.0 and 9.9.1
-
Fixed a bug in NTL_EXEC_INDEX (actually, in
BasicThreadPool::relaxed_exec_index)
that would cause an error to be incorrectly raised in some
situations
-
Fine tuned some crossover points
2016.05.30: Changes between NTL 9.8.1 and 9.9.0
-
Added
examples on how to use documentation on NTL's thread pools
and parallel for loops:
see here
-
The build procedure now puts files config_log.h
and wizard_log.h
in NTL's include directory.
These files contain comments that document what choices were
made during the build process,
including the CXXAUTOFLAGS value.
-
Added elts() method to UniqueArray and AlignedArray
(for compatibility with Vec class)
-
Added get() and release() methods to OptionalVal
-
Made constructors for PartitionInfo and BasicThreadPool
explicit
-
Cleaned up some pointer issues in mat_lzz_p.c (mainly academic)
-
Definition of NTL_TLS_LOCAL_INIT ensures that var names
a local reference, regardless of the implementation
-
Allow p.move(q), where p is a UniquePtr<T>,
q is a UniquePtr<Y>,
and Y* converts to T*.
-
Introduced PreconditionedRemainder class
for faster reduction of a ZZ modulo a fixed long.
This is intended to make Chinese Remaindering type computations faster
-
for the time being,
this is an undocumented feature which may be modified or removed
in a future release
-
Introduced ll_type and related routines which perform
a restricted set of operations on a long-long-like type.
It can be implemented via inline asm, and is a cleaner
interface and sometimes faster.
On x86-64/gcc platforms, the assembly code version is
used and gives a modest speed boost.
For all other platforms (including x86-64 with clang or icc),
the assembly code is not used.
I should really dynamically enable the assembly via the performance
tuning wizard, but I don't do this yet.
To explicitly disable the assembly code,
configure with NTL_DISABLE_LL_ASM=on.
-
for the time being,
this is an undocumented feature which may be modified or removed
in a future release
2016.04.29: Changes between NTL 9.8.0 and 9.8.1
-
Fixed an annoying issue that could cause a unnecessary
ambiguities in client code when compiling with NTL_EXCEPTIONS=on
2016.04.26: Changes between NTL 9.7.1 and 9.8.0
2016.04.20: Changes between NTL 9.7.0 and 9.7.1
-
Extended the performance improvements in
mat_lzz_p
to include the gauss, kernel,
and image routines
-
Generally improved
performance for all of the mat_lzz_p,
including an implementation of Strassen for matrix multiplication.
-
Added the matrix/column vector solve routines
to all other matrix classes (for consistency).
-
Fixed a compile-time bug that occured on certain platforms
(mainly Windows).
-
Made some of the steps in configure and make
a bit more quiet (look at .log files for outputs).
2016.03.12: Changes between NTL 9.6.4 and 9.7.0
-
Changes to mat_lzz_p module:
-
Improved performance of mul, inv, solve,
and determinant routines:
-
more cache friendly
-
thread boosted
-
for small p (up to 23 bits), exploits
AVX and FMA instructions (when available)
-
depending on many things,
the new code can be anywhere between
1.5x and 70x (!) times faster than the old code
(part of that speedup up can be attributed to just how
awful some of the old code was, rather than
how brilliant the new code is)
-
on the SandyBridge and Haswell machines I was able to test,
the new code is comparable in speed
to
FFLAS/FFPACK
-
Added "relaxed" versions of inv, solve, and
determinant,
which also now work for prime powers, not just primes
-
Added a new variant of solve routine to solve A*x = b
for column vectors
- Changes to BasicThreadPool
module:
-
Added NTL_EXEC_RANGE and other functionality which makes writing
"parallel for loops" simple (very similar to OpenMP),
and the same source code will work regardless of whether
threads or thread boosting is enabled.
-
Backward incompatibilities:
-
NTLThreadPool is no longer directly accessible:
new access functions are provided
-
Got rid of method SplitProblems, and made a more general/abstract
class PartitionInfo
-
Miscellaneous:
-
Improved crossover points for GF2X division
-
Made access to thread local variables used in NTL faster
by using GCC's __thread in place of thread_local,
wherever possible
-
Improved performance of vec_long to vec_zz_p conversion
-
Made AVX and FMA detection more robust, requiring LP64
-
Added InvModStatus for long's
-
Bumped FILE_THRESH to 1e12
2016.01.30: Changes between NTL 9.6.3 and 9.6.4
-
Streamlined some of the installation scripts,
so now the "heurstic selection of compiler flags"
and the "nonstandard feature testing" procedures are more structured
so as to be easier to extend in the future -- it is beginning to
act more like a sort of "autoconf".
-
Fixed a couple of "buglets" in the header files.
2016.01.26: Changes between NTL 9.6.2 and 9.6.3
-
Some changes to the installation procedure:
-
For the Unix distribution, NTL_GMP_LIP is now
on by default, which means that by default, NTL will use
GMP.
-
By default, the configuration script will attempt a
"native'' build by passing -march=native
as a compiler flag.
Most modern compilers support this, but the configuration script will
check to make sure.
-
The NTL_PCLMUL flag (which enables the use of
Intel's PCLMUL instruction) is now automagically set by the
Wizard script.
-
The build script automatically checks for availability of Intel
AVX intrinsics, which may be used to better
optimize certain code.
-
A new modular composition implemention for zz_pX.
This makes modular composition up to 3x faster, depending
on several factors.
-
Improved performance for polynomial factoring over zz_pX
using CanZass,
using the improved modular composition routine (above)
and better choice of baby step / giant step parameters.
This leads to a 1.1x to 1.8x speedup, depending on several factors.
-
Improved robustness of quad_float implementation:
it should now work correctly on platforms that are too
liberal in their use of FMA instructions.
2015.11.13: Changes between NTL 9.6.1 and 9.6.2
-
More small tweaks and a new configuration variable:
NTL_MAXIMIZE_SP_NBITS=off
# Allows for 62-bit single-precision moduli on 64-bit platforms.
# By default, such moduli are restricted to 60 bits, which
# usually gives *slightly* better performance across a range of
# of parameters.
2015.11.13: Changes between NTL 9.6.0 and 9.6.1
-
Streamlined some awkard code in g_lip_impl.h.
-
Made QuickTest a bit quicker.
-
Fixed some documentation/packaging problems.
2015.11.10: Changes between NTL 9.5.0 and 9.6.0
-
More performance tuning for ZZ_pX arithmetic.
-
Added configuration variable CXXAUTOFLAGS,
which is dynamically (and heuristically) set by the configuration
script.
This way, CXXFLAGS is not modified by the script.
2015.10.20: Changes between NTL 9.4.0 and 9.5.0
2015.9.22: Changes between NTL 9.3.0 and 9.4.0
2015.7.9: Changes between NTL 9.2.0 and 9.3.0
-
Fixed a compilation error that arose with NTL_LEGACY_SP_MULMOD=on.
-
Added a new call back routine ErrorMsgCallback.
See tools.txt.
This is mainly to help with NTL integration withing SAGE.
2015.5.23: Changes between NTL 9.1.1 and 9.2.0
-
Completed the transition away from floating-point arithmetic
for the implementation of single-precision modular arithmetic.
The current implementation should allow 60-bit moduli on
64-bit platforms that support a 128-bit extended integer
type (this is the case for current gcc, clang, and icc
compilers).
One can still revert to the "classical" (pre-9.0) implementation
using double-precision arithmetic (which imposes a 50-bit limit),
or to the "long double" implementation introduced in v9.0 (60-bit limit).
Note that one must compile NTL with GMP to get any of these improvements.
It would have perhaps been better to use GMP's longlong.h
facility instead of relying on compiler support for extended
integer types.
However, at the moment, it is a bit inconvenient to use longlong.h
as a freestanding header file.
This might change in the future.
For details, see here,
including the comments entitled "Compatibility notes".
Programming notes: MulMod(a, b, n) is equivalent to
mulmod_t ninv = PrepMulMod(n); MulMod(a, b, n, ninv).
Compared to the older, floating-point implementation, the
relative cost of computing ninv is higher in the new regime.
In a loop where n is invariant, the compiler should
"hoist" the computation of ninv, so it is only done once.
However, it is usually better to precompute and store ninv,
and use the second form of MulMod, with ninv passed
as a parameter (NTL does this internally quite consistently).
The performance of MulMod(a, b, n, ninv) is somewhat faster
in the new implementation.
Where possible, one should use MulModPrecon, which is faster still
(useful in situations where both n and b are invariant).
-
A number of general performance improvements.
2015.5.16:
Changes between NTL 9.1.0 and 9.1.1
-
Fixed a bug introduced in 9.1.0 that prevented conversions
between Vec<GF2> and Vec<T>.
2015.5.2:
Changes between NTL 9.0.2 and 9.1.0
2015.3.29:
Changes between NTL 9.0.1 and 9.0.2
-
Made a small change to single-precison MulMod
that enables slightly better compiler optimizations
(compiler can "hoist" the computation of 1/n
out of a loop, so the variant with extra mulmod_t
arg becomes somewhat less essential).
2015.3.27:
Changes between NTL 9.0.0 and 9.0.1
-
Fixed a small bug that prevented compilation a certain platforms.
2015.3.27:
Changes between NTL 8.1.2 and 9.0.0
-
With much trepidation, I have introduced a (hopefully minor)
backward incompatibility into NTL.
The interface to the single-precision modular arithmetic
routines has been modified slightly.
This interface change allows for more flexible and more
efficient implementation of these routines,
which play a crucial role at many levels in NTL.
Basically, these changes to the interface abstract away
some implementation details that arguably should never been there
in the first place.
By coding to the new interface, NTL clients will be able to
benefit from
the current and future improvements.
In particular, on 64-bit x86/GCC platforms, single precision
moduli can now be up to 60 bits, rather than 50 bits.
While some operations may in fact be a little slower, the most important
ones (like MulModPrecon) should not be.
Using larger moduli speeds up a number of things, like ZZ_pX
arithmetic, as fewer primes need to be used in Chinese Remaindering steps.
Other applications benefit from larger moduli as well.
It is expected that most NTL clients will not be affected at all.
Moreover, any code that needs to be updated will be detected
by the compiler, and the updates should be simple and mechanical.
There is also a configuration flag that will enable the legacy
interface (although this is not recommended practice).
For details, see here,
including the comments entitled "Compatibility notes".
-
Other changes:
-
Previous versions of NTL relied (at least by default) on some
undefined behavior regarding integer arithemtic
(namely, that in a few key code sequences, signed integer
overflow just "wraps around").
All of this undefined behavior has been replaced by
(much more desirable) implementation-defined behavior
(namely, that conversion from unsigned to signed works as expected).
As in the past, the NTL_CLEAN_INT can be used to
avoid all of these issues (but with the new code, this should
truly be academic).
For details, look here.
-
By request, added a function xdouble exp(const xdouble& x),
which is equivalent to xexp(to_double(x)).
For details, look here.
2015.1.31:
Changes between NTL 8.1.1 and 8.1.2
-
Corrected a bug that could affect the log
function in a multi-threaded execution.
2015.1.30:
Changes between NTL 8.1 and 8.1.1
-
Corrected a syntax error in SmartPtr.h,
which most compilers don't seem to complain about, but some
do.
-
Added --tag=CXX to the some lines
in the makefile to keep libtool happy.
2015.1.9:
Changes between NTL 8.0 and 8.1
-
Corrected an oversight in the matrix template class.
With this new version, one may safely copy and assign
objects of type Mat<ZZ_p>
and Mat<GF2E> out of context (i.e.,
under a different or undefined modulus).
More generally, the copy constructor for Mat<T>
now relies only on the copy constructor for Vec<T>
and the assignment operator for Mat<T>
relies only on the assignment operator and copy constructor
for Vec<T>.
The goal since v6.2 has been to allow all modular types (ZZ_p, etc.)
and all types derived from them (vectors, polynomials, matrices, etc.)
to be safely copy constructed and assigned out of context.
Hopefully, this goal has now been reached.
2014.12.24:
Changes between NTL 7.0.2 and 8.0
- Exceptions!
This is another major milestone for NTL, and hence the big
version number bump (this will be the last of these big bumps
for a while).
Prior to this version, error handling consisted of "abort with an error message".
To enable exceptions in NTL, configure with NTL_EXCEPTIONS=on.
You will also need a C++11 compiler for this to work properly
(and if you don't enable exceptions, any old C++98 compiler will
work, as always).
With exceptions enabled, errors are reported by throwing an appropriate
exception.
Of course, this was the easy part.
The hard part was making NTL's code exception safe,
which (among other things) means that no resources (i.e., memory)
are leaked when an exception is thrown.
This required a very painful top-to-bottom scrub of the whole library.
Despite major changes to the code base and many internal
interfaces, the external (i.e., documented) interfaces remain
completely unchanged.
More details are available here.
-
Improved performance of ZZ_pX arithmetic for both classic
and GMP-based long integer packages.
-
Made copy constructor and assignment operators
for fftRep and FFTRep safe "out of context",
which extends to the classes zz_pXModulus and ZZ_pXModulus.
-
Made mechanism for establishing "unique ID's" (used for temporary
file name generation and default pseudo-random number seeds)
more robust.
2014.12.15:
Changes between NTL 7.0.1 and 7.0.2
-
Fixed bug introduced in v7.0 affecting RR and quad_float input routines,
which would leave the RR precision variable in an incorrect state.
-
Fixed a bug introduced in the v6.2 that affected the append routines
for ZZ_p and GF2E, which would lead to incorrect memory allocation
(which, if triggered, should just have led to an error message and abort, rather than
incorrect results).
This bug also affected the new Vec constructor introduced in v7.0
(and again, only for ZZ_p and GF2E).
2014.11.14:
Changes between NTL 7.0.0 and 7.0.1
-
Fixed critical bug in new bit-reverse-copy routine.
Large degree polynomial multiplication code was buggy
in v7.0.
Now it's fixed and properly tested.
2014.11.8:
Changes between NTL 6.2.1 and 7.0
- Thread safety!
This is a major milestone for NTL (and hence a bump in the
major version number).
However, to actually use it, you will need a "bleeding edge"
C++ that supports C++11 concurrency features.
Most importantly, the C++11 storage class thread_local
needs to be fully and correctly implemented.
Some compilers claim to support it, but are very buggy to the point of
being useless.
All I can say is, as of right now, I have been able to
successfully build and test a multi-threaded NTL program
using GCC 4.9.2 on a Red Hat Linux distribution.
I don't think any pre-4.9.x version of GCC will work.
And unfortunatly, I don't think any compiler (GCC or CLANG)
on any current Mac will work, but I haven't been able to directly
test this.
As time goes on, I expect C++ compilers will provide the
necessary support.
In the meantime, you can try it out and see if it works for you.
Configure with the NTL_THREADS flag turned on and see
what happens.
The test program ThreadTest that runs as the last step
of make check will let you know if it works.
If not, you can try building GCC 4.9.2 yourself.
It is actually not that hard!
See the portability and implementation section
for more information.
In any case, if threads don't work for you, just don't use them.
Everything still works as before using almost any compiler.
-
I changed the stream input behavior to conform to wider
C++ practice (and with an eye towards am exception safe future).
Previously, if an attempt to read an NTL object failed, the
good old Error function was called, printing an error message,
and aborting your program.
Now, NTL just quietly sets the ``fail bit'' of the stream.
The second example here illustrates this.
Hopefully, this change will not cause too many problems,
but if it does, configure NTL with the NTL_LEGACY_INPUT_ERROR
flag on to get the old behavior back.
-
To further simplify future development, I've dropped support
for legacy C++ standard header files.
That is, NTL always uses <iostream>
rather than <iostream.h>.
This shouldn't be a problem for anyone by now, as these
lagacy header files have been gone from standard C++
since 1998.
Also, by default, NTL components are still wrapped in the NTL
namespace, but for backward compatibility, you can still put
them in the global namespace by configuring NTL
with the NTL_LEGACY_NO_NAMESPACE flag.
-
Implemented a cache-friendy "bit reverse copy" routine for doing
FFT's. This is the COBRA algorithm from Cater and Gatlin, "Towards an
optimal bit-reversal permutation algorithm", FOCS 1998.
This does seem to help a bit.
Getting rid of "bit reverse copy" would be even better,
but this would take more work and break a number of interfaces.
-
Made some minor improvements to ZZX multiplication routines
to get better locality of reference.
Improvement is nominal.
-
Fixed a small issue in the left-shift ZZ routine:
it was allocating one word more than necessary in some cases.
-
Added new Vec constructor, so
T a;
Vec<T> v(INIT_SIZE, n, a);
|
is equivalent to
T a;
Vec<T> v;
v.SetLength(n, a);
|
In both cases, the copy constructor for T
is used.
-
I've added some more documentation about what I plan on
doing with NTL in the future, as well as a "wish list"
of what I hope others might contribute.
See the roadmap section for
more details.
2014.8.26: Changes between NTL 6.2 and 6.2.1
-
Fixed syntax problem in NTL/vector.h
2014.8.21: Changes between NTL 6.1 and 6.2
-
I added explicit constructors corresponding to promotions.
For example:
ZZ w = ZZ(1); // legal
ZZ w(1); // legal
ZZ w{1}; // legal in C++11
ZZ w = 1; // not legal
|
Also added new names for the "monomial constructors", e.g.,
ZZX(INIT_MONO, i, c) is now preferred to ZZX(i, c),
although the old constructors are still there.
There are also new constructors like ZZX(INIT_MONO, i)
for making monic monomials.
-
An subtle but important change is that now objects from
classes that represent residue class rings with a
dynamically installed modulus, i.e.,
ZZ_p, zz_p, ZZ_pE, lzz_pE, GF2E,
may now be used a bit more flexibly.
It is critical that such objects created under one modulus are not used in
any non-trivial way "out of context", i.e., under a different (or undefined)
modulus. However, for ease-of-use, some operations may be safely
performed out of context. These safe operations now include: the default and copy
constructor, the destructor, and the assignment operator. In addition it is
generally safe to read any object out of context (i.e., printing it out, or
fetching its underlying representive using the rep() function).
(In the past, it was generally unsafe to use the the default and copy constructors
out of context, which also prevented vectors and polynomials
of such objects from being copied out of context.)
The implementations of Vec<ZZ_p> and Vec<GF2E>
are still specialized to manage memory more
efficiently than in the default implementation of Vec<T>.
Contiguous elements in such an array are allocated in a contiguous region of
memory. This reduces the number of calls to the memory allocator, and
leads to greater locality of reference.
A consequence of
this implementation is that any calls to SetLength on such a vector will
need to use information about the current modulus, and so such calls should
only be done "in context". That said, it is still safe to construct a
such a vector using the default or copy contructor, and to assign or append one
to another "out of context".
-
For the classes ZZ_p, ZZ_pE, zz_pE,
and GF2E, added explicit "allocation" and "no allocation" contructors
(invoked with INIT_ALLOC and INIT_NO_ALLOC) and special member function
allocate(). This allows one to explicitly determine exactly when
space for such objects is allocated.
By default, no space is allocated (this is different from prior versions of NTL),
except for ZZ_p's that are a part of a Vec<ZZ_p>
and GF2E's that are a part of a Vec<GF2E>
-
Added new classes ZZ_pPush, ZZ_pEPush,
zz_pPush, zz_pEPush, GF2EPush.
These allow one to conveniently backup and optionally install
a new modulus in one step:
{ ZZ_pPush push(p); ... }
|
will save the current modulus and install p as the
new modulus; when the destructor for push is invoked,
the old modulus will be re-installed.
-
Made the one-arg constructors for all the various "context" classes
(e.g., ZZ_pContext) explicit.
-
As a general aid to generic programming, I've added a
bunch of typedef's using consistent naming conventions
to all of the main arithmetic classes.
E.g., ZZ_p::poly_type is a typedef for ZZ_pX.
There are a whole bunch of these.
See the documentation for the individual classes for details.
-
Got rid of a few esoteric compilation modes:
-
All files are now C++ files, and should be compiled
using a C++ compiler. In older versions, some files
could be compiled either as C or C++.
-
The flag NTL_GMP_HACK is no longer supported.
GMP may still be used using the NTL_GMP_LIP flag,
which is still highly recommended for high-performance applcations.
-
The flags NTL_SINGLE_MUL and NTL_FAST_INT_MUL
are no longer recognized.
These were really outdated and esoteric.
-
I have started working towards making NTL thread safe.
It is not as difficult as I thought it would be, but it is still
a work in progress.
So far I have identified all global variables, and either got
rid of them, or tagged them as "thread local".
So, although there are still some global variables, they will
all eventually be "thread local".
In particular, things like the current ZZ_p modulus
will be a thread-local global variable.
There are a few remaining trouble spots I've tagged:
these mostly involve lazy initialization of tables;
I have a plan for making this code thread safe using
nearly lock-free coding techniques.
I will hopefully get this done within the next 6-12 months.
One thing that is slowing me down is the lack of availibility
of C++11 features that I need to do some of this,
but it will come.
The main reason for getting rid of the esoteric compilation modes
mentioned above is to make it easier to do this thread-safety work.
2014.03.13: Changes between NTL 6.0 and 6.1
-
Added support for "user defined" FFT primes for zz_p.
See the functions
static void zz_p::UserFFTInit(long p);
zz_pContext::zz_pContext(INIT_USER_FFT_TYPE, long p);
|
in the lzz_p module.
2013.02.15: Changes between NTL 5.5.2 and 6.0
-
Replaced the old template-like macros for vectors, matrices,
and pairs with true template classes: Vec<T>,
Mat<T>, and Pair<S,T>.
For backwards compatibilty, all the names that were used
in previous versions (e.g., vec_ZZ_p, mat_ZZ_p)
have been replaced with appropriate typedefs.
For many years, I resisted the temptation of using templates,
because compiler support was very inconsistent.
But that no longer seems to be the case.
This change, while rather sweeping, should create very few,
if any, incompatibilities with existing software.
The biggest issue would be for software that uses the
old template-like macros: such macro invocations can simply be
replaced with appropriate typedefs.
-
Made the conversion interface more complete and uniform.
Also, using template notation, one can and should now write
conv<ZZ>(a) instead of to_ZZ(a)
(for backward compatibility, all the old names to_XXX
are still there, but many new conversions are not available
under these old names).
There are many new conversions provided.
Moreover, whenever there is a conversion from a ring R
to a ring S, there is a corresponding, coefficiet-wise
conversion from the polynomial ring R[X] to the
polynomial ring S[X].
In addition, using the template mechanism, there are
generic conversions for vectors and matrices.
For example, if there is a conversion from S to T,
then there is automatically a corresponding component-wise
conversion from Vec<S> to Vec<T>.
-
Introduced a more general mechanism for accessing GF2's
in packed structures via indexing (see the class
ref_GF2 in the GF2 module).
-
Employed ideas from David Harvey to make the single-precision
FFT faster (about twice as fast in many cases).
This speeds up many higher-level operations.
See: Faster arithmetic for number-theoretic transforms.
J. Symb. Comp. 60 (2014) 113-119.
-
Fixed all known bugs.
2009.08.14: Changes between NTL 5.5.1 and 5.5.2
-
New routines MulAddTo and MulSubFrom
for computing x += a*b and x -= a*b,
where x and a are ZZ's and
b is a ZZ or a long.
In the case where b is a long,
this may be much faster than writing
mul(t, a, b); add(x, x, t).
See ZZ.txt for details.
These new routines are used in a number of places in
NTL to get faster algorithms (for example, the LLL routine).
-
Fixed a relatively benign indexing bug in GF2EX
discovered by Berend-Benjamin Tams using the valgrind tool.
2009.05.05: Changes between NTL 5.5 and 5.5.1
- If using GMP (via either NTL_GMP_LIP
or NTL_GMP_HACK), then the new version (4.3.0) of
GMP implements the XGCD functionality differently,
so that the coefficients do not always agree with those returned by
the classical extended Euclidean algorithm.
This version of NTL corrects the coefficients, so that the
"classical" coefficients are always produced, regardless
of GMP's implementation.
This version of NTL also works
around a bug in GMP 4.3.0's XGCD code
(although that bug should be fixed in GMP 4.3.1).
-
The configure script has been slightly modified:
there is a new configuration variable DEF_PREFIX,
whose value can be used to set PREFIX, GMP_PREFIX,
and GF2X_PREFIX in one stroke.
Also, the (somewhat esoteric) configure variables
GMP_LIBDIR, GMP_INCDIR,
GF2X_LIBDIR, and GF2X_INCDIR
have slightly different meanings now.
2009.04.08: Changes between NTL 5.4.2 and 5.5
-
Added the ability to generate a shared library
(with help from Tim Abbott). Details.
-
Fixed some standardization issues
(with help from Tim Abbot):
default location of installed documentation files now conforms
to standards; use of EOF now conforms to standards.
-
Added a callback mechanism to NTL's error reporting function.
See ErrorCallback in tools.txt.
-
Added support for the GF2X library for speeding up
arithmetic in GF2X (with help from Emmanuel Thomé).
Details.
-
In conjuction with the above, I also changed the
GF2X so that it works better with very large polynomials:
large blocks of memory are released, recursive HalfGCD algorithms
are used for large polynomials.
-
Fixed a bug in void TraceMod(zz_p& x, const zz_pX& a, const zz_pXModulus& F) (reported by Luca De Feo).
-
Fixed a performance issue in various versions of SetCoeff
(reported by Luca De Feo).
-
Fixed the declaration of mat_zz_p transpose(const mat_zz_p& a)
(reported by Benoit Lacelle).
2008.03.05: Changes between NTL 5.4.1 and 5.4.2
-
Fixed a bug in the sub(ZZ_pEX, ZZ_pE, ZZ_pEX)
and sub(zz_pEX, zz_pE, zz_pEX) routines (reported by Charanjit Jutla).
Under certain circumstances, these could outout wrong answers.
2007.05.09: Changes between NTL 5.4 and 5.4.1
-
Fixed rounding bug in expm1 (reported by Paul Zimmermann).
-
Fixed memory leak in several LLL routines (reported by Friedrich Bahr).
-
Fixed infinite loop in several LLL routines
(this only occurred on machines, like x86, with double rounding).
-
Improved GF2X timing tests (suggested by Paul Zimmermann).
2005.03.24: Changes between NTL 5.3.2 and 5.4
2004.05.21: Changes between NTL 5.3.1 and 5.3.2
-
Some bug fixes.
-
Re-wrote SqrRootMod to make it run faster.
2002.12.17: Changes between NTL 5.3 and 5.3.1
-
Fixed a bug affecting the BuildIrred routines
for ZZ_pEX and zz_pEX.
2002.07.05: Changes between NTL 5.2 and 5.3
-
Minimized and isolated constructs that do not adhere to C/C++
standards,
and added flags NTL_CLEAN_INT and NTL_CLEAN_PTR
which force stricter compliance with these standards
[more details].
-
Added functions IsWhiteSpace, CharToIntVal,
and IntValToChar to the tools module
[more details].
-
Added methods allocated, position1 to generic vector classes
[more details].
-
Added method allocated to the class vec_GF2
[more details].
-
Added conversion routines from unsigned int/long to int, long, float, and double
[more details].
-
Added routines AddPrec, SubPrec, etc., to the RR
module, and declared the practice of directly assigning to the variable
RR::prec obsolete
[more details].
-
Fixed a number of minor bugs.
2001.07.19: Changes between NTL 5.1a and 5.2
2001.06.08: Changes between NTL 5.0c and 5.1a
Some minor fixes and additions.
Completely backward compatible.
-
Added a routine LatticeSolve() for finding integer
solutions to linear systems of integer equations.
[more details]
-
Modified the stragey used by the LLL() and image()
routines in the LLL package to deal
with linear dependencies.
The new strategy guarantees better worst-case bounds on the
sizes of intermediate values.
I'm not sure if it will have any serious practical impact, though.
-
Added some "partial ISO modes" so that one can use
some of the features of Standard C++,
even if ones compiler does not yet support all of the features.
-
Bug fix: routine determnant() in mat_GF2.h
was not visible to the linker because of a typo in mat_GF2.c.
-
Made a "smarter" script for selecting the GetTime()
function.
This fixes an installation problem on Cygwin/Windows 95 platforms.
I hope it doesn't create more problems than it solves, though.
-
Added some extra documentation for installation under
Windows/MS Visual C++.
[more details]
-
Changed some names like c_lip.c to c_lip_impl.h.
This should avoid some potential installation problems.
-
Throw away first 256-bytes of arc4 streams to improve quality of
the pseudo-random number generator.
This may change the precise behavior of some programs.
-
Other minor, internal modifications.
2001.02.19: Changes between NTL 5.0b and 5.0c
Fixed a naming problem in the Windows distribution.
The Unix distribution is unaffected.
2001.02.19: Changes between NTL 5.0a and 5.0b
Fixed a typo in vec_ulong.c that causes a compile error
on some platforms.
2001.02.19: Changes between NTL 4.3a and 5.0a
Changes between NTL 4.2a and 4.3a
This is backward compatible with previous versions.
-
Improved the performance of ZZ_pX arithmetic when using
GMP.
The GMP version is also more space efficient
(the pre-computed tables are much smaller).
These improvements are most marked for very large p (several
thousand bits).
The only thing unsatisfactory about this state of affairs is that
vis a vis the GMP version, the pure
LIP code is asymptotically slower by more than a constant factor,
and is is also less space efficient.
Perhaps I'll get around to rectifying this imbalance someday.
To do this, I need a sub-quadratic division with remainder routine for LIP.
At any rate, the differences only become seriously noticible when
p has more than a few thousand bits.
-
Some other small adjustments here and there.
Changes between NTL 4.1a and 4.2a
This is backward compatible with previous versions.
-
Hacked the big integer code so that NTL uses GMP
(the GNU Multi-Precision library).
This is done in such a way as to get most of the benefits of GMP
with a reasonable amount of effort, and while maintaining complete backward
compatability and minimizing the risk of introducing bugs.
Some arithmetic operations
on some platforms may execute two to three times
faster if using GMP. [more details]
-
Simplified the installation procedure on Unix systems by
providing a simple configuration script so that setting
various configuration variables can be done without
editing the makefile and config.h file.
[more details]
-
Added function GenGermainPrime
to efficiently generate random Germain primes, i.e., primes p
such that 2p+1 is also prime. [more details]
-
Added a function random to generate random quad_floats.
[more details]
-
Added an ifdef in tools.h that allows
one to suppress the declaration of min and max
functions in NTL client programs;
these were causing problems when writing 'Windows applications'.
-
Implemented a faster algorithm for initializing the
ZZ_p auxilliary data structures.
-
Polished up a few other minor things in the code and documentation.
Changes between NTL 4.0a and 4.1a
This is backward compatible with previous versions.
-
Made some changes that should make NTL compile smoothly
using any variation of the C++ language between traditional and
ISO Standard.
These changes do not affect the documented NTL interface or the
behaviour of NTL.
-
Added a flag NTL_STD_CXX in the config.h file.
Setting this flag causes all of NTL to be "wrapped" in namespace NTL,
and that part of the standard library used by NTL is "wrapped"
in namespace std.
This should greatly help with the namespace pollution problem.
Changes between NTL 3.9b and 4.0a
This is backward compatible with previous version.
-
Attached the GNU General Public License to NTL.
-
Fixed two bugs:
-
one in ReconstructRational which resulted in a crash on some inputs;
-
one in exp(RR) (and by implication in pow(RR,RR)),
which led to wrong answers on 64-bit machines when computing exp(x)
for x > 2^53.
-
Increased some inconvenient limiting bounds, including a restriction on the
FFT.
Changes between NTL 3.9a and 3.9b
This is a minor revision of 3.9a.
-
Improved time and space efficiency of the HNF routine
(see HNF.txt).
The old version was based on the description in Henri Cohen's book,
which was not really properly optimized.
Changes between NTL 3.8b and 3.9a
This is backward compatible with previous versions.
-
Modified the installation script somewhat, adding
a configuration wizard that sets the flags in
config.h "automagically".
This works for the Unix version only.
-
Improved the xdouble input/output and ascii to xdouble
conversion.
The old version could be a bit flaky when reading/writing
very large numbers.
The new I/O routines also attain better accuracy.
-
Improved conversion routines between xdouble
and ZZ/RR.
-
Improved the RR output routine.
The new version should be more accurate and also
completely platform independent.
-
Added the following routines to the RR package:
{Trunc,Floor,Ceil,Round}ToZZ, round
RoundToPrecision, MakeRR
random
See RR.txt for details.
-
Improved the accuracy of quad_float input/output,
and the accuracy of conversion between quad_float and RR.
-
Made the timing function somewhat more robust.
-
Hacked the Unix installation script so that it works
more smoothly with Cygnus tools under Windows.
-
Fixed a few other, small problems.
Changes between NTL 3.8a and 3.8b
This is a minor revision of 3.8a.
-
Fixed a bug, a memory leak in routine gauss for mat_ZZ_pE
and mat_zz_pE.
-
Fixed a minor problem in config.h.
-
Tightened up some size checks, so that now some nice "size invariants"
are guaranteed, e.g., for a ZZ n,
NumBits(NumBits(n)) <= NTL_BITS_PER_LONG-4
|
Similarly for the type GF2X.
Of course, on most platforms, one will run out of memory before
these bounds are exceeded, but they are nevertheless convenient.
Changes between NTL 3.7a and 3.8a
This is backward compatible with previous versions.
-
Added conversion routines from unsigned int
and unsigned long to
ZZ, RR, xdouble, and quad_float.
-
Added routines GF2XFromBytes and BytesFromGF2X
for conversion between byte vectors and polynomials over GF(2),
along with routines NumBits and NumBytes
for such polynomials.
See GF2X.txt for details.
-
Added a hack in the ZZX factorizer
to exploit polynomials of the form g(x^k).
This can be disabled by setting the variable ZZXFac_PowerHack
to zero.
See ZZXFactoring.txt
for details.
-
Improved the hensel system solver solve1.
See mat_ZZ.txt for details.
-
Changed documentation for RationalReconstruction
to reflect the Wang, Guy, Davenport bounds.
See ZZ.txt for details.
-
Improved the routine GenPrime a bit.
-
Some other small tweaks here and there.
No real bug fixes.
-
Polished the documentation a bit, adding more examples.
Changes between NTL 3.6b and 3.7a
This is backward compatible with previous versions.
-
Added a "rational reconstruction" routine.
See the routine ReconstructRational in ZZ.txt.
-
Added another routine for solving linear systems over ZZ
that is based on Hensel lifting, rather than Chinese Remaindering.
It can be significantly faster in some cases.
See the routine solve1 in mat_ZZ.txt).
-
Some performace tuning, especially CRT and polynomial interpolation code.
-
Various documentation corrections.
-
Added more "overflow checks" here and there to ensure programs crash gracefully
when certain things get too big.
-
Fixed a "benign" bug (i.e., it would never get triggered on any of today's
machines).
-
Removed references to <malloc.h>, which were unnecessary,
non-standard, and caused problems on some platforms.
Changes between NTL 3.6a and 3.6b
Bug fixes.
Changes between NTL 3.5a and 3.6a
This version is backward compatible with 3.5a.
-
A few small bug fixes and performance enhancements.
-
Changed to the ZZX factoring routines that in some
cases yield dramatic performance improvements
(more details).
Changes between NTL 3.1b and 3.5a
Please note. This version is NOT completely backward compatible.
Summary of changes:
-
Improved performance of the "all integer" LLL routine.
-
Put in a better pseudo-random number generator,
and added ZZ/byte array conversions.
-
Improved performance of primality test, and added a
more convenient routine GenPrime.
-
Overloaded NTL's vector placement "new" operator in a different
way to avoid conflicts with standard C++ library.
-
Renamed many macros.
-
Renamed header files.
-
Made some changes to the packaging
the installation procedure.
Renamed Macros.
I renamed many macros defined in NTL header files.
The reason is that I want to minimize namespace pollution.
Someday, NTL will be wrapped in a namespace, and when that happens
the only remaining namespace pollution problems will be caused by macros.
Eliminating all macros from NTL is not feasible.
Instead, all NTL defined macros now begin with the prefix "NTL_",
which reduces the namespace pollution to an ecceptable level.
You will probably not be affected by this, unless you
do some low level hacking using a macro like ZZ_NBITS
(now called NTL_NBITS), or unless you create your
own NTL vectors using a macro like ntl_vector_decl
(now called NTL_vector_decl).
For a complete list of affected names, see names.txt.
Adapting to this name change should be painless, as there is a
program to translate source files from the old naming convention to the new.
The file "newnames.c",
can be compiled as either a C or C++
program.
The program is a "filter" that copies its input to its output,
replacing all the old macro names by the new macro names.
In the WinNTL distribibution, "newnames.c" is called
"newnames.cpp" and is located in the directory
"newnames".
Renamed header files.
The names of header files themeselves pollute another (extra-linguitsic) namespace.
To alleviate this problem, the header files have been renamed.
Instead of
one now should write
The only exceptions are the old header files "ntl_vector.h",
"ntl_matrix.h", and "ntl_pair.h", which are now called
<NTL/vector.h>, <NTL/matrix.h>, and
<NTL/pair.h>.
Installation procedure.
Now all
NTL flags like NTL_LONG_LONG, NTL_AVOID_FLOAT, etc., can now be set
by editing the special file "include/NTL/config.h".
See details in that file.
The reason for this change is that this allows all of these settings
to be made when NTL is configured and built.
Clients of NTL will then automatically use consistent settings.
One should not set these flags on the compiler command line as previously.
Pentium/Linux people should no longer have to worry
about the NTL_X86_FIX flag. NTL now psychically deduces
the "right thing to do", although if its psychic abilities fail,
you can override it with flags in "include/NTL/config.h".
The "packaging" in the Unix distribution is slightly
different, but hopefully nicer.
Among other things, the tar file now unpacks into a sub-directory of the current directory.
See the unix installation section
for more details.
The Windows zip file now also
unpacks into sub-directory.
My apologies.
Although these changes are minor, they will cause some NTL
users some inconvenience.
I apologize for this.
I really, really hope there are no more changes like this
(see my roadmap of NTL's future).
Changes between NTL 3.1a and 3.1b
Defined functions div(GF2X,GF2X,GF2) and div(GF2X,GF2X,long),
which had not been defined in earlier versions.
Affected file: GF2X.c.
Most programs never use this, and most linkers do not complain
if these are missing (but some do).
Changes between NTL 3.0f and 3.1a
This version is backward compatible with previous versions.
-
Added floating point LLL routines based on Givens rotations,
instead of classical Gramm-Schmidt orthogonalization.
This is a more stable, but somewhat slower, method.
See LLL.txt for details.
-
Added support for irreducible trinomials and pentanomials
over GF(2). The GF2XModulus routines,
and by extension, the GF2E routines,
now exploit moduli of this special form.
The new routine BuildSparseIrred in GF2XFactoring
builds irreducibles of this form.
-
Also implemented a faster modular inversion routine
for GF2X, and improved the performance of ZZ_pX
multiplication for small degree polynomials.
Changes between NTL 3.0e and 3.0f
Changes between NTL 3.0 and 3.0e
Changes between NTL 2.0 and 3.0
-
Added functionality:
-
Added classes vec_GF2 and mat_GF2 for fast linear algebra over GF(2).
-
Added classes ZZ_pE, ZZ_pEX, zz_pE, zz_pEX, supporting polynomial
arithmetic over extension rings/fields over prime fields.
-
Added John Abbott's pruning heuristic to the ZZX factoring routine.
-
Speeded up multiplication in zz_pX for small p (this also helps
the ZZX factoring routine).
-
Added some some transcendental functions (e.g., exp, log, pi) to RR.
-
Added verbose mode and pruning to the XD and RR variants of LLL.
-
Improved programming interface:
with this version, I've taken an the opportunity to
give the programming interface a "professional facelift".
In previous releases, I've tried to maintain backward compatability
as much as possible, but to make the badly needed improvements
to the interface that I've made with this release, this was not
possible.
NTL 3.0 is not backward compatable with NTL 2.0.
I apologize to NTL users for this, but it is a bit of painful
medicine that should only be necessary to take just this one time
(but then as a C++ programmer, you must already
be used to suffering ;-).
Just about all of the incompatabilities are detectable by the compiler.
See below for a detailed list of the changes and
some tips on making the transition.
The new interface is much more enjoyable to work with,
and I don't foresee any changes to the interace in the future.
Here is a broad overview of the changes:
Compatibility
Here is a detailed list of the changes to the programming
interface.
-
The names of the classes
BB, BB_p, BB_pX
have been changed to
GF2X, GF2E, GF2EX
-
There is also a class GF2 to represent GF(2).
Many of the functions relating to BB, BB_p, BB_pX
had argument and return-value types of type long
that are now of the more appropriate type GF2.
This change was needed so that the interface would be consistent
with that of the new classes
ZZ_pE, ZZ_pEX, zz_pE, zz_pEX.
-
The explicit conversion operator from GF2X
(the new BB) to GF2EX (the new BB_pX)
has different semantics: it now performs a coefficient lift,
instead of creating a constant polynomial.
-
The conversion operator "<<" has been retired.
Now instead of
one writes
Operator "<<" is now used for shift operations.
-
Every conversion routine now has a corresponding functional version
which has the name to_T, where T is the result type.
These new names replace old names that were less consistent.
So instead of
one writes
-
The names of the routines
ZZ_pInit, zz_pInit, zz_pFFTInit, GF2EInit
have been changed to
zz_p::init, zz_p::init, zz_p::FFTInit, GF2E::init
-
The names of the routines
and, or, xor
for class ZZ have
changed to
bit_and, bit_or, bit_xor,
because the new C++
standard defines these as reserved words.
-
The function LowBits for ZZ is now called trunc.
-
Polynomial inversion mod X^n has changed from inv
to InvTrunc.
-
Modular trace, norm, minimum polynomial and characteristic
polynomial have changed from
trace, norm, MinPoly, IrredPoly, CharPoly
to
TraceMod, NormMod, MinPolyMod, IrredPolyMod, CharPolyMod
-
For the class ZZX, the functions
DivRem, div, rem, /, %, /=, %=
have new semantics when dividing by non-monic polynomials.
The old semantics are provided by new routines
PseudoDivRem, PseudoDiv, PseudoRem.
-
The UpdateMap routines have slightly different semantics:
in versions < 3.0, the output always had length n;
now high-order zeroes are stripped.
-
The classes ZZ_pBak, zz_pBak, etc.,
have just slightly different semantics; I can't imagine
any reasonable program detecting a difference.
-
The assignment operator and copy constructor for the class RR
have different semantics: they now produce exact copies, instead
of rounding to current precision.
-
All of the NTL compiler flags now start with NTL_
to avoid name space problems.
-
All of the files "zz_p.h", vec_zz_p.h", etc., have been eliminated.
Use instead the names "lzz_p.h", "vec_lzz_p.h", etc.
Tips on making the transition
-
Apply this sed script to make
most of the necessary syntactic changes.
-
Re-compile old NTL programs with the flag
-DNTL_TRANSITION
See flags.txt for details on how
this will help your compiler detect remaining incompatabilities.
In particular, any uses of operator <<
in its old role as a conversion operator will cause the compiler
to raise an error.
You can then convert all of these to the new notation.
Changes between NTL 1.7 and 2.0
-
Implementation of classes BB (polynomials over GF(2))
and BB_pX (polynomials over GF(2^n)).
-
A more consistent and natural interface, including arithmetic operators
and a disciplined use of automatic conversion.
So now one can write
instead of
mul(x, a, b);
add(x, x, c);
|
as one must in older versions of NTL.
The operator notation leads to somewhat less efficient code,
and one can always use the old notation in situations
where efficiency is critical.
Despite the new programming interface,
care has been taken to ensure backward compitability;
pre-existing programs that use NTL should still work.
-
Windows port.
-
Added compile-time flag that allows one to exploit
"long long" data type if it exists (this especially helps on Pentium/Linux
platforms).
-
Added compile-time flag to get better quad_float code on
Pentium/Linux platforms.
-
A few bug fixes and performance tuning.
Changes between NTL 1.5 and NTL 1.7
-
Incorporation of Keith Briggs' quadratic precision package.
-
Much faster and more robust lattice basis reduction,
including Schnorr-Horner "volume heuristic" for Block Korkin
Zolotarev reductions, and a new quadratic precision LLL variant
that is much more robust.
-
A few bug fixes.
Changes between NTL 1.0 and NTL 1.5
-
Implementation of Schnorr-Euchner algorithms for
lattice basis reduction, including deep insertions and
block Korkin Zolotarev reduction.
These are significantly faster than the LLL algorithm
in NTL 1.0.
-
Implementation of arbitrary-precision floating point.
-
Implementation of double precision with extended exponent range,
which is useful for lattice basis reduction when the coefficients
are large.
-
Faster polynomial multiplication over the integers,
incorporating the Schoenhagge-Strassen method.
-
Compilation flags that increase performance on machines
with poor floating-point performance.
-
Sundry performance tuning and a few bug fixes.